Bastelecke > Smarthome > ioBroker und Node-RED > Erste Flows und die grundsätzliche Funktionsweise von Node-RED
Wir haben nun Node-RED installiert, können auf die Objekte unseres ioBrokers zugreifen und haben bereits unseren ersten Flow erstellt. Doch Node-RED kann deutlich mehr, als nur beim Tasterdruck das Licht ein- und auszuschalten.

Die bisherige Umsetzung war eine sehr einfache Verkettung zweier MQTT-Nodes, bei der wir im Grunde nichts anderes gemacht haben, als einen Schaltzustand auszulesen und das Ergebnis an ein anderes Objekt weiterzuleiten. Lasst euch jedoch von der bunten, grafischen Oberfläche nicht täuschen: Node-RED ist weit mehr als nur eine weitere Umsetzung von Blockly, der JavaScript-Entwicklungsumgebung von Google, bei der man einzelne Funktionsbausteine per Mausklick zusammensetzt.
Vielmehr stellt Node-RED den Informationsfluss grafisch dar. Die einzelnen Nodes legen fest, wie eine Information verarbeitet wird – und wir sind vollkommen frei darin, was am Ende dabei herauskommen soll. Wir können fertige Nodes verwenden, die kleine Teilaufgaben erledigen, oder eigene, komplexe Funktionen in JavaScript schreiben.
Mit Node-RED habt ihr ein mächtiges Entwicklerwerkzeug zur Hand, mit dem ihr volle Kontrolle über die Funktionsweise aller Elemente eurer Smart-Home-Steuerung erhaltet. Keine Angst: Der erste Kontakt mag überfordern – insbesondere, wenn man etwas wie Blockly erwartet. Doch hat man die grundlegende Funktionsweise erst einmal verstanden und gemerkt, wie simpel sich manche Dinge hier umsetzen lassen (für die man in Blockly stundenlang Funktionsbausteine verschieben müsste), dann kommt der Fortschritt ganz von selbst.
Grundlegende Funktionsweise
Bei Computerprogrammen geht es immer um die Verarbeitung von Informationen. Man spricht vom EVA-Prinzip: Eingabe – Verarbeitung – Ausgabe. Wir geben irgendeine Information ein, diese wird in definierter Weise verarbeitet und als Ergebnis ausgegeben.
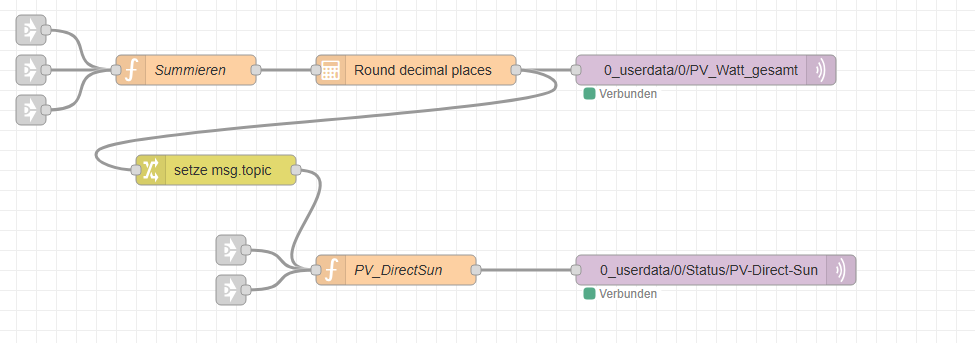
Ob es – wie im oben gezeigten Flow – ein Schaltwert ist, der einfach nur weitergeleitet wird, zwei Zahlen, die addiert werden, oder komplexe logische Verknüpfungen: Am Ende steht immer ein Ergebnis.
In Node-RED ist diese Information das msg-Objekt. Die Art, wie es von Node zu Node weitergereicht wird, entscheidet die Verdrahtung der einzelnen Nodes miteinander.
Ein msg-Objekt kann mehrere Eigenschaften haben. Besonders häufig begegnet uns msg.payload. Diese Eigenschaft bezeichnet den eigentlichen Informationsinhalt. Eine weitere wichtige Eigenschaft ist msg.topic, also quasi der „Titel“ der Nachricht.
Im einfachen Schaltbeispiel ist uns der Titel egal – wir verwenden nur msg.payload, das je nach Schalterstellung true oder false ist, und leiten es direkt an die Lampe weiter. Sobald jedoch mehrere Informationen gleichzeitig in einen Node fließen, muss anhand des Topics unterschieden werden, um die richtige Verarbeitung zu gewährleisten.
Beispiel: Subtraktion bei Bedingung

In diesem Flow übergebe ich drei Werte an eine Funktion. Wenn wert1 den Wert true hat, soll wert3 von wert2 abgezogen werden. wert1 ist also ein boolescher Schaltzustand, wert2 und wert3 sind Zahlen.
Wie im Beispiel zu sehen, hat der Funktions-Node nur einen Eingang, über den alle drei Werte übergeben werden. Wichtig: Ein Wert liegt niemals dauerhaft auf einer Node-Verbindung an. Es handelt sich lediglich um eine Nachricht, die verarbeitet und dann weitergereicht wird.
Auch senden die drei Werte nicht „brav“ nacheinander – sie treffen in zufälliger Reihenfolge ein, abhängig von den Änderungen im ioBroker. Die Funktion erkennt anhand von msg.topic, ob es sich um wert1, wert2 oder wert3 handelt. Diese Werte werden zwischengespeichert und erst verarbeitet, wenn alle drei vorhanden sind.
Ein klein wenig JavaScript
Die Funktion habe ich in JavaScript geschrieben. Dafür braucht man keine tiefgreifenden Kenntnisse – Grundverständnis von Syntax und Node-RED genügt.
Hier der Code zur Subtraktionsfunktion:
let key = "subtraktion1"; // ← bei weiterer Instanz z. B. "subtraktion2"
let data = flow.get(key) || {};
// Eingehende Daten speichern
if (msg.topic === "wert1") {
data.wert1 = msg.payload === true || msg.payload === "true";
} else if (msg.topic === "wert2") {
data.wert2 = Number(msg.payload);
} else if (msg.topic === "wert3") {
data.wert3 = Number(msg.payload);
}
flow.set(key, data);
// Wenn wert1 true → Subtraktion
if (data.wert1 === true &&
typeof data.wert2 === "number" &&
typeof data.wert3 === "number") {
msg.payload = data.wert2 - data.wert3;
return msg;
// Wenn wert1 false → nur wert2 durchreichen
} else if (data.wert1 === false &&
typeof data.wert2 === "number") {
msg.payload = data.wert2;
return msg;
}
return null;Gehen wir das Ganze Schritt für Schritt durch:
let
Mit dem Befehl let deklarieren wir eine Variable. In den Anfängen von JavaScript hat man das noch mit var gemacht. Allerdings sind Variablen, welche mit var deklariert werden, global gültig. Mit jedem Aufruf der Funktion würde die Variable überschrieben werden, was zur Folge hätte das sich, bei mehrfacher Verwendung der Funktion, Fehler durch falsche Werte einschleichen würden. Der Befehl let verhindert das, indem durch ihn deklarierte Variablen nur innerhalb der gerade laufenden Funktion Gültig sind. Außerhalb der Funktion existieren diese nicht und nach Beendigung der Funktion verschwinden sie wieder. Somit brauchen wir weder aufpassen das wir den Namen einer Variable, im gesamten Flow, nicht doppelt vergeben, noch alle Variablennamen bei mehrfacher Verwendung der Funktion ändern.
flow.get – flow.set
Dieses ist unser persistenter Speicher. Alles was wir uns über den Aufruf der Funktion hinweg merken wollen, legen wir dort ab. Um die Daten wiederzufinden, wird ein Keyword verwendet. Dieses ist das einzige, was wir bei Mehrfachverwendung der Funktion in einem Flow immer wieder ändern müssen, da wir hier auf den Speicher des Flows zugreifen und dieser für alle unsere Funktionen Gültigkeit hat. Um es mir einfacher zu machen, habe ich das Keyword zu Beginn in der Variable key festgelegt und muss es somit nur einmal, an zentraler Stelle der Funktion ändern. Mit let data = flow.get(key) || {} erstelle ich die lokale Variable data als Array und lade den Inhalt hinein, der hinter dem vergebenen Keyword im Flow gespeichert ist. Sollte hier noch nichts hinterlegt sein, erstelle ich eine leeres Array; dafür die Alternativanweisung {}.
Anschließend prüfe ich mit if ob es sich bei dem msg.topic, also dem Titel der übermittelten Nachricht, um Wert1, Wert2 oder Wert3 handelt und speichere diesen entsprechend hinter Wert1, Wert2 oder Wert3 in meinem data-Array. Damit die Daten auch nach Beendigung der Funktion weiterhin erhalten bleiben, schreibe ich sie anschließend mit flow.set(key, data) wieder im persistenten Speicher des Flows.
return
Im zweiten Teil des Scripts prüfen ich nun ob alle Werte vorhanden sind. Wenn der erste Wert True ist, ziehe ich Wert3 von Wert2 ab, anderenfalls reiche ich einfach nur Wert2 weiter durch. Das Ergebnis meiner Berechnungen gebe ich dann wieder als msg.payload mit dem Befehl return aus. Die Nachricht verlässt dann den Node und wird an den nächsten Node der Verkettung weiter gereicht. In meinem Fall an den Calculator-Node, welcher das Ergebnis auf eine Nachkommastelle rundet.
Sobald ein return-Befehl erreicht wird, wird die Funktion beendet. Die nachfolgenden Zeilen Code werden dann nicht mehr ausgeführt. Das führt dazu das die letzte Codezeile return null nur erreicht wird, wenn nicht alle 3 Werte vorliegen und damit keine der Bedingungen erfüllt ist. Dann wird einfach überhaupt nichts ausgegeben und somit auch nicht der nächste Node getriggert.
Zusammenfassung: Funktionsweise des Scripts
Mit jeder eintreffenden Nachricht wird die Funktion neu aufgerufen. Sie lädt sich die bereits im Flow gespeicherten Werte, es wird anhand des Topic entschieden welcher Wert übermittelt wurde und entsprechend im Flow dauerhaft gespeichert oder aktualisiert. Dann wird weiter geprüft ob alle 3 benötigten Werte vorliegen und wenn ja ein Ergebnis berechnet. Dieses Ergebnis wird dann weiter gegeben. Wenn noch Werte fehlen, dann wird die Funktion am Ende beendet, ohne irgendetwas zu senden. In diesem Fall hat sie nur den empfangenen Wert im Speicher des Flow, für ihren nächsten Aufruf hinterlegt.
Dieses entspricht auch der grundsätzlichen Funktionsweise von Node-RED. Immer wenn ein Wert als Nachricht in einen Flow gelangt, wird er entsprechend der Programmierung der Nodes weiter gereicht. Er bleibt nicht auf der Verbindung zwischen zwei Nodes abrufbar, sondern wird nur einmal durchgereicht. Jetzt kann ich den Wert im Node entweder nach einem programmierten Muster verändern und direkt wieder ausgeben, oder im dauerhaften Speicher des Flows zwischenspeichern und zur späteren Verwendung, wenn beispielsweise das Script beim Eintreffen eines zweiten Wertes wieder aufgerufen wird, aus diesem Flow-Speicher zurück holen und mit dem neu eingetroffenen Wert zusammen verarbeiten.
Anhand dieses Beispiels haben wir nun gelernt wie Node-RED intern arbeitet, was mit Informationen passiert, wie sie weiter gereicht werden und haben uns sogar bereits das erste Beispiel für einen selbst erstellten Funktions-Node angesehen.
In Zukunft werden wir sicher noch die eine oder andere Funktion schreiben, Die werden jedoch kaum umfangreicher sein. Die meisten Berechnungen und Zuweisungen lassen sich mit paar wenigen Zeilen Code bewerkstelligen. Alles was ich euch hier zeige könnt ihr gerne kopieren und weiterverwenden. Ich achte beim Erstellen meiner Funktionen gezielt darauf das sie sich dynamisch an ihre Umgebung anpassen und damit frei wiederverwendbar und flexibel einsetzbar sind. Und für vieles gibt es auch bereits fertige Nodes, die keine einzige Zeile Code benötigen.
Wenn ihr bis hierhin durchgehalten habt, dann habt ihr die grundlegende Funktionsweise von Node-RED verstanden und das Schlimmste hinter euch. Als nächstes befassen wir uns damit, wie wir mit einer großen Anzahl an MQTT Abrufen richtig umgehen, ohne unsere Systeme in die Knie zu zwingen.